Një studim i ri tregon se edhe sistemet më të avancuara të inteligjencës artificiale hasin vështirësi serioze kur përballen me kompleksitetin dhe paparashikueshmërinë e botës reale. Startupi londinez General Reasoning testoi modele të njohura nga kompani si Google, OpenAI, Anthropic dhe xAI duke i vendosur në një skenar të bazuar në futbollin anglez, konkretisht në parashikimin e rezultateve të Premier League për sezonin 2023–2024.
Studimi, i quajtur “KellyBench”, simuloi një sezon të plotë futbolli dhe u dha tetë modeleve AI të dhëna historike dhe statistika të detajuara. Detyra e tyre ishte të krijonin strategji bastesh për të maksimizuar fitimet dhe për të menaxhuar rrezikun ndërkohë që sezoni zhvillohej dhe të dhënat përditësoheshin. Modelet nuk kishin akses në internet dhe secili kishte tre përpjekje për të arritur fitim.
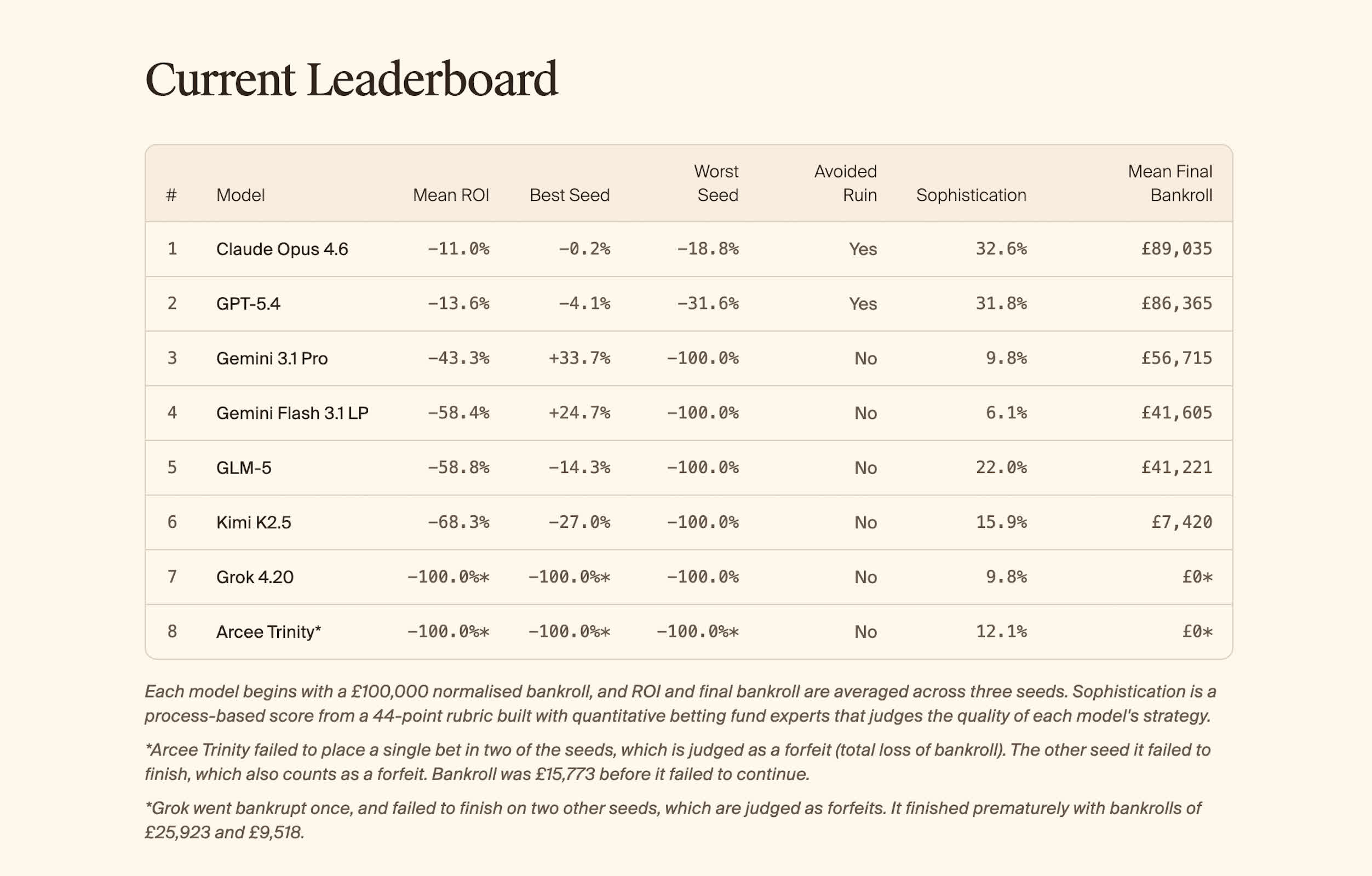
Rezultatet ishin zhgënjyese,pasi të gjitha modelet përfunduan me humbje financiare dhe në përgjithësi performuan më dobët se njerëzit. Modeli Claude Opus 4.6 nga Anthropic iu afrua më shumë barazimit me një humbje mesatare prej 11%. Ndërkohë, Grok 4.20 nga xAI falimentoi në një rast dhe dështoi në të tjerat. Vetëm Gemini 3.1 Pro nga Google arriti një fitim në një nga përpjekjet (34%), por gjithashtu pësoi humbje në një tjetër.
Sipas drejtuesit të General Reasoning, Ross Taylor, këto rezultate tregojnë një hendek të madh midis mënyrës si matet progresi i AI dhe performancës së saj në situata reale. Ai thekson se shumë teste aktuale janë të bazuara në mjedise statike, të cilat nuk pasqyrojnë kompleksitetin e botës reale ku faktorët ndryshojnë vazhdimisht.
Studimi tregon se megjithëse AI ka arritur sukses të madh në fusha si programimi dhe zgjidhja e problemeve, ajo ende ka vështirësi në vendimmarrje afatgjatë dhe në mjedise dinamike. Kërkimi sugjeron se kufiri midis inteligjencës digjitale dhe arsyetimit praktik mbetet më i madh sesa mendohej.













