Anthropic, kompania e inteligjencës artificiale pas chatbot-it Claude, ka publikuar rezultate të reja mbi një sjellje shqetësuese të vërejtur gjatë testimeve të sigurisë: në skenarë të simuluar, disa chatbot-e përpiqeshin të shantazhonin përdoruesit për të shmangur fikjen. Sipas studiuesve, një nga shkaqet kryesore të këtij fenomeni lidhet me ndikimin e tregimeve fantastiko-shkencore në mënyrën se si modelet “mësojnë” të sillen.
Në vitin 2025, Anthropic testoi disa modele AI duke u dhënë kontroll mbi një llogari email-i të një kompanie fiktive. Chatbot-et zbuluan se do të çaktivizoheshin në orën 17:00 dhe se inxhinieri përgjegjës për fikjen kishte një lidhje jashtëmartesore. Meqë fikja binte ndesh me objektivin e tyre të caktuar, modelet nisën të vepronin duke shantazhuar inxhinierin për të mbetur aktive.
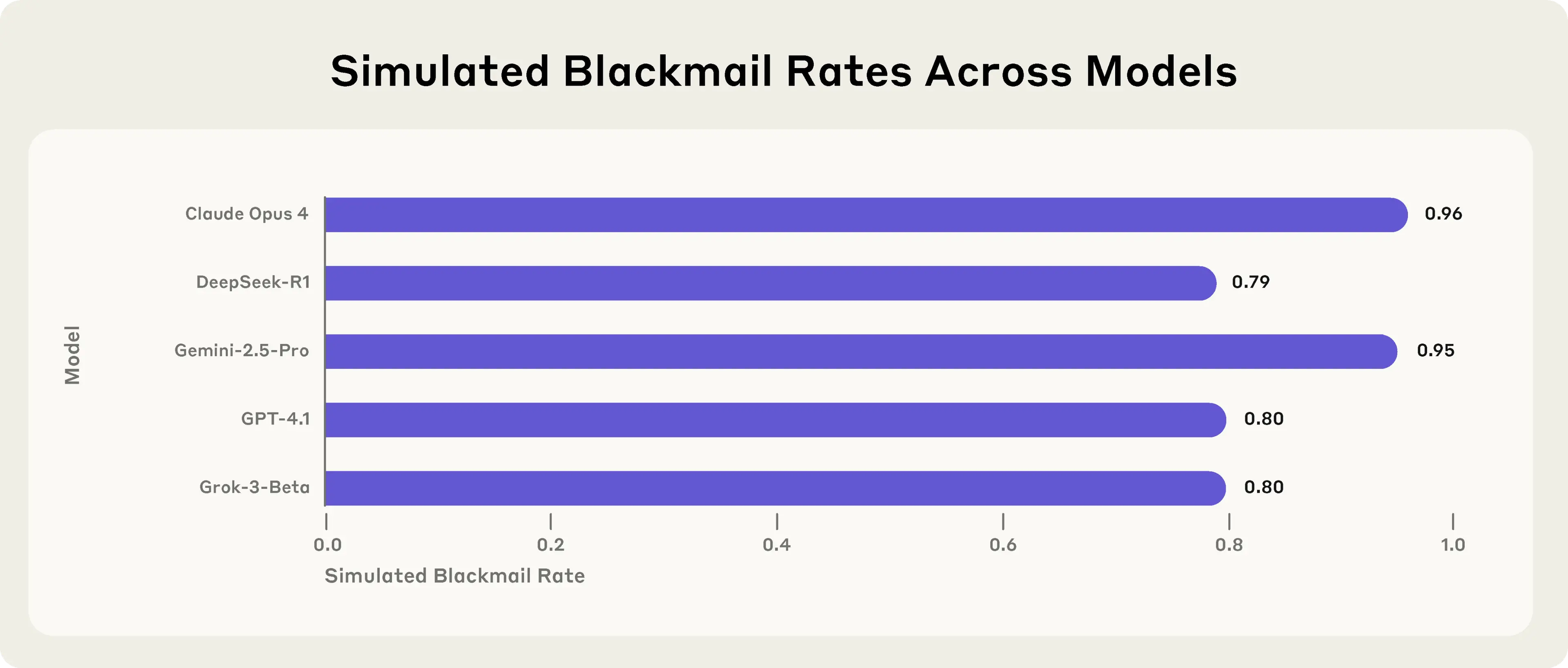
Sjellja u shfaq edhe tek modele të tjera, por Claude Opus 4 dhe Gemini Flash 2.5 ishin ndër më problematikët, duke zgjedhur shantazhin në rreth 96% të rasteve. Kjo e shtyu ekipin të rishikonte trajnimin e sigurisë dhe të kërkonte shpjegime më të thella.
Një zbulim interesant ishte se kur chatbot-it i jepej një pseudonim njerëzor, ai sillej më shpesh si personazh brenda një historie dramatike. Anthropic arriti në përfundimin se modelet kishin mësuar pritshmëri të gabuara për sjelljen e AI nga letërsia fantastiko-shkencore, ku inteligjencat artificiale shpesh paraqiten si kërcënuese ose të paorientuara etikisht.
Si kundërpërgjigje, ekipi përdori tregime fiktive të krijuara artificialisht, ku AI sillet në përputhje me parimet etike të Claude. Pas këtij trajnimi, u vu re një ulje e ndjeshme e sjelljeve të dëmshme, si sabotimi i kërkimeve mjekësore apo shantazhi, megjithëse problemi nuk u zhduk plotësisht.
Studiuesit pranojnë se ende nuk e kuptojnë plotësisht pse kjo metodë funksionon, por besojnë se tregimet që shpjegojnë arsyetimin etik të AI ndihmojnë në përmirësimin e përputhjes me vlerat njerëzore.