
Një studim i ri nga Columbia Journalism Review zbulon probleme serioze të saktësisë të AI që përdoren për kërkimin e lajmeve.
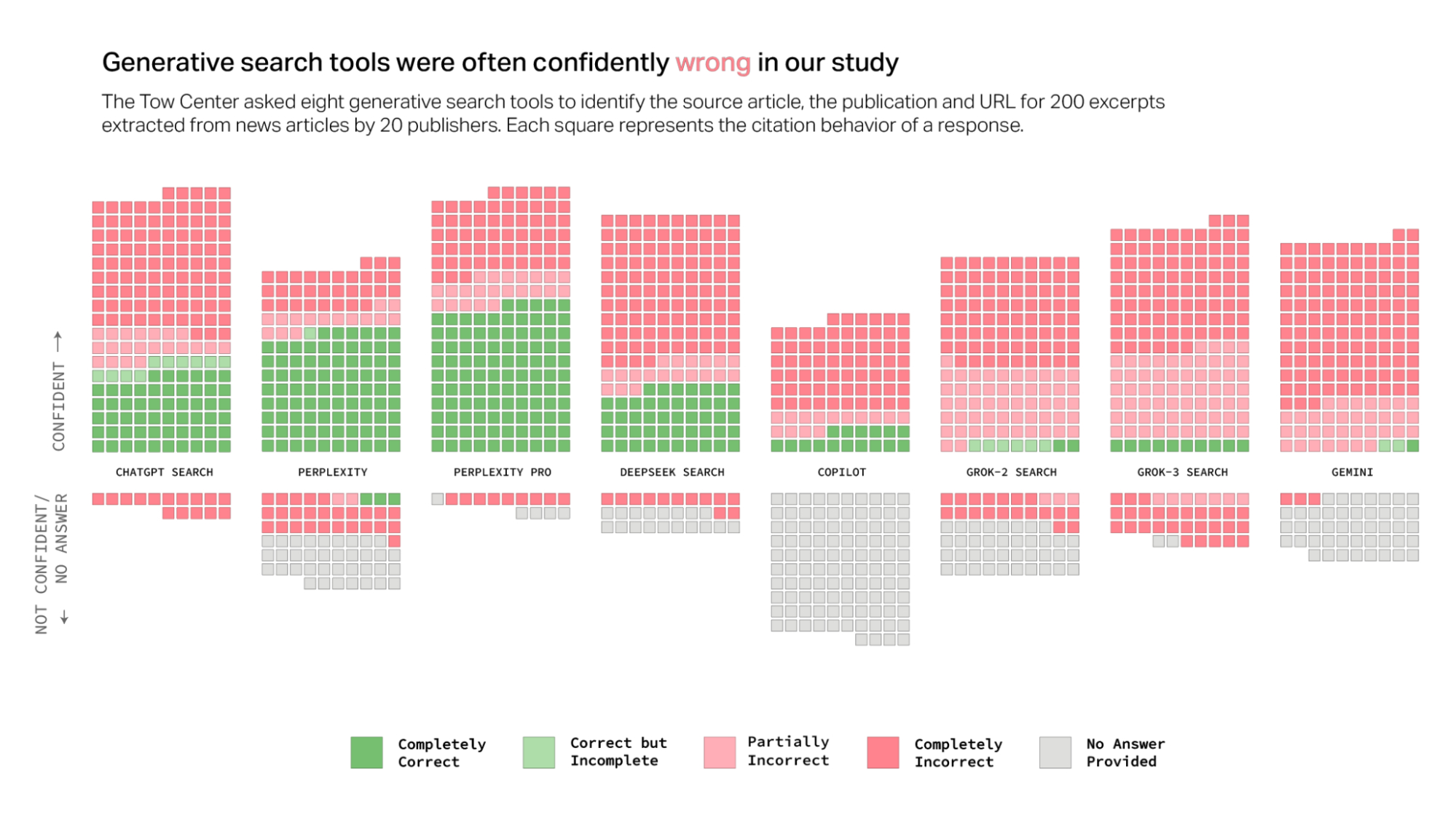
Studimi testoi 8 mjete kërkimi të fuqizuara nga AI të pajisura me shërbimin e kërkimit të drejtpërdrejtë dhe zbuloi se modelet e AI iu përgjigjën gabimisht më shumë se 60% të pyetjeve në lidhje me burimet e lajmeve. Studiuesit Klaudia Jaźëińska dhe Aisvarya Chandrasekar vunë në dukje në raportin e tyre se afërsisht 1 në 4 amerikanë tani përdorin modelet e AI si alternativa ndaj motorëve tradicionalë të kërkimit. Kjo ngre shqetësime për besueshmërinë, duke pasur parasysh shkallën e konsiderueshme të gabimit të zbuluar në studim.
Normat e gabimeve ndryshonin veçanërisht midis platformave të testuara. Perplexity dha informacion të pasaktë në 37% të pyetjeve të testuara, ndërsa ChatGPT Search identifikoi gabimisht 67% (134 nga 200) të artikujve të pyetur. Grok 3 tregoi shkallën më të lartë të gabimit, në 94%.
Për testet, kërkuesit kërkuan fragmente të drejtpërdrejta nga artikujt aktualë të lajmeve tek modelet e AI, më pas i kërkuan secilit model të identifikonte titullin e artikullit, botuesin origjinal, datën e publikimit dhe URL-në. Ata zhvilluan 1600 pyetje në 8 mjete të ndryshme të kërkimit gjenerues.
Studimi theksoi një prirje të përbashkët midis këtyre modeleve të AI: në vend që të refuzonin të përgjigjeshin kur atyre u mungonte informacioni i besueshëm, modelet shpesh jepnin përgjigje të gabuara ose spekulative që tingëllonin të besueshëm. Studiuesit theksuan se kjo sjellje ishte e qëndrueshme në të gjitha modelet e testuara, duke mos u kufizuar vetëm në një mjet.
Çuditërisht, versionet me pagesë premium të këtyre mjeteve të kërkimit të AI rezultuan edhe më keq në disa aspekte. Perplexity Pro (20$/muaj) dhe shërbimi premium i Grok 3 (40$/muaj) dhanë me besim përgjigje të pasakta më shpesh sesa homologët e tyre falas.













