Dy studime të fundit hedhin dyshime serioze mbi pretendimet e kompanive të teknologjisë se modelet e tyre të inteligjencës artificiale janë në gjendje të “arsyetojnë”. Në realitet, këto modele shpesh nuk bëjnë gjë tjetër veçse përsërisin modele të mësuara, duke prodhuar përgjigje bindëse, por jo domosdoshmërisht të zgjuara apo logjike.
Një studim nga Apple testoi disa modele të avancuara në lojën logjike Tower of Hanoi, që kërkon planifikim dhe arsyetim hap pas hapi. Ndërsa modelet përballuan nivelet më të thjeshta me 2-3 disqe, performanca e tyre ra ndjeshëm me shtimin e kompleksitetit. Ato gabonin në rregulla, kundërshtonin hapat e mëparshëm, ose jepnin zgjidhje të pavlefshme — edhe kur nxisnin vetë mendimin logjik (“chain-of-thought”).
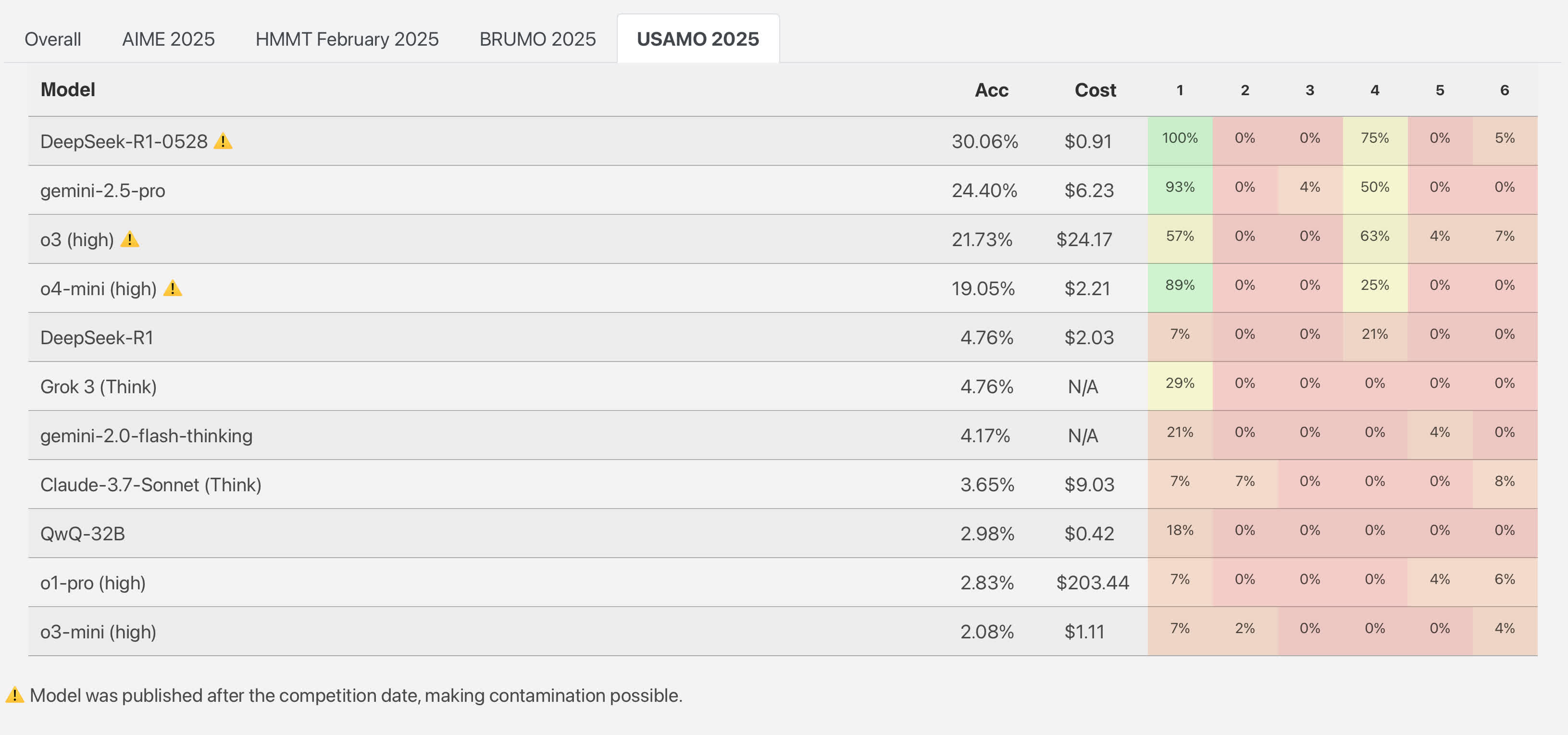
Një studim tjetër nga ETH Zurich dhe INSAIT testoi modelet në detyra të Olimpiadës Matematike të SHBA 2025. Asnjë model nuk dha zgjidhje të plota dhe korrekte. Për shembull, DeepSeek R1 mori 30% të pikëve totale, Gemini 2.5 Pro i Google mori vetëm 24% të pikëve, ndërkohë, modeli o3-mini i OpenAI kaloi vetëm 2%.
Eksperti Gary Marcus i quajti këto rezultate “shkatërruese” për modelet e mëdha gjuhësore, duke theksuar se ato dështojnë në detyra që studentët e vitit të parë të inteligjencës artificiale i zgjidhin pa problem që në vitin 1957.
Disa, si Sean Goedecke, sugjerojnë se dështimi tregon më shumë për mënyrën si këto modele përpiqen të shmangin lodhjen logjike, duke kërkuar rrugë të shkurtra në vend të zgjidhjes hap pas hapi.
Të dy studimet nënvizojnë faktin se, përtej paraqitjes së përpunuar, shumica e këtyre modeleve nuk zotërojnë aftësi të vërtetë arsyetimi – vetëm një simulim bindës të tij.